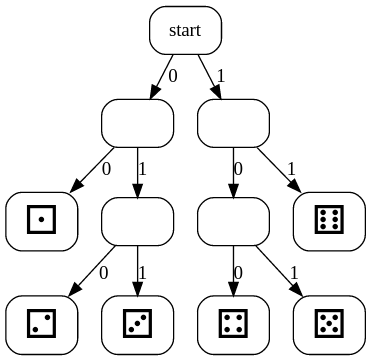
The sequence of bits 111001 decodes to "tttct". Starting at the left, the first bit is a 1, which only starts a "t". There are two more of these, and then we encounter a 0. This could start any of the other three characters, but because it is followed by another 0, it can only represent "c". This leaves a 1 at the end, which is a "t".
Coding - Compression
7.3. Huffman coding
A common way to compress data is to give short codes to common symbols, and long codes to things that are rare. For example, Morse code represents the letter "e" with a single dot, whereas the letter "z" is two dashes followed by two dots. On average, this is better than using the same length code for every symbol.
But working out the optimal code for each symbol is harder than it might seem – in fact, no one could work out an algorithm to compute the best code until a student called David Huffman did it in 1951, and his achievement was impressive enough that he was allowed to pass his course without sitting the final exam.
The technique of Huffman coding is the final stage in many compression methods, including JPEG, MP3, and zip. The purpose of Huffman coding is to take a set of "symbols" (which could be characters in text, run lengths in RLE, pointer values in a Ziv-Lempel system, or parameters in lossy systems), and provide the optimal bit patterns with which they can be represented. It's normally presented as a way of compressing textual documents, and while it can do that reasonably well, it works much better in combination with Ziv-Lempel coding (we'll get to that later).
But let's start with a very simple textual example. This example language uses only four different characters, and yet is incredibly important to us: it's the language used to represent DNA, which is made up of sequences of four characters A, C, G and T. For example, the 4.6 million characters representing an E.coli DNA sequence happens to start with:
agcttttcattct
Using a simple data representation, with four characters you'd expect to represent each character using two bits, such as:
a: 00 c: 01 g: 10 t: 11
The 13 characters above would be written using 26 bits as follows – notice that we don't need gaps between the codes for each pair of bits.
00100111111111010011110111
But we can do better than this. In the short sample text above the letter "t" is more common than the other letters ("t" occurs 7 times, "c" 3 times, "a" twice, and "g" just once). If we give a shorter code to "t" then 54% of the time (7 out of 13 characters) we'd be using less space. For example, we could use the codes:
a: 010 c: 00 g: 011 t: 1
Then our 13 characters would be coded as:
0100110011110001011001
which is just 22 bits.
This new code can still be decoded even though the lengths are different. For example, try to decode the following bits using the code we were just using. The main thing is to start at the first bit on the left, and match up the codes from left to right:
111001
Decoding 111001 Spoiler!
But is the code above the best possible code for these characters (as it happens, this one is optimal for this case)? And how can we be sure the codes can be decoded? For example, if we just reduced the length for "t" like this:
- a: 00
- c: 01
- g: 10
- t: 1
try decoding the message "11001".
Decoding 11001 Spoiler!
This message can't be worked out with certainty because the original could have been "tgc" or "ttat". The clever thing about a Huffman code is that it won't let this happen.
David Huffman's breakthrough was to come up with an algorithm to calculate the optimal bit patterns based on how frequent each character is. His algorithm is fairly simple to do by hand, and is usually expressed as building up structure called a "tree".
For example, the code we used above (and repeated here) corresponds to the tree shown below.
a: 010 c: 00 g: 011 t: 1
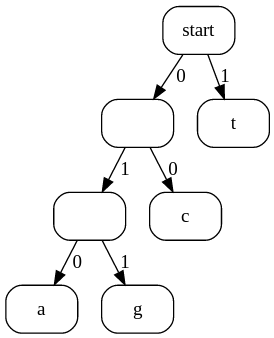
To decode something using this structure (e.g. the code 0100110011110001011001 above), start at the top, and choose a branch based each successive bit in the coded file. The first bit is a 0, so we follow the left branch, then the 1 branch, then the 0 branch, which leads us to the letter "a". After each letter is decoded, we start again at the top. The next few bits are 011..., and following these labels from the start takes us to "g", and so on. The tree makes it very easy to decode any input, and there's never any confusion about which branch to follow, and therefore which letter to decode each time.
The shape of the tree will depend on how common each symbol is. In the example above, "t" is very common, so it is near the start of the tree, whereas "a" and "g" are three branches along the tree (each branch corresponds to a bit).
What kind of tree is that? Curiosity
The concept of a "tree" is very common in computer science. A Huffman tree always has two branches at each junction, for 0 and 1 respectively. The technical terms for the elements of a tree derive from botanical trees: the start is called the "root" since it's the base of the tree, each split is called a "branch", and when you get to the end of the tree you reach a "leaf".
To write a computer program that stores a Huffman tree, you could either use a technique called pointers to represent the branches, or (in most fast implementations) a special format called a "Canonical Huffman Tree" is used, but you don't need to worry about that implementation detail to understand the principle that they use to compress data.
Huffman's algorithm for building the tree would work like this.
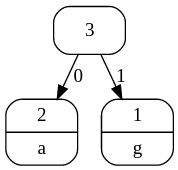
First, we count how often each character occurs (or we can work out its probability):
a: 2 times c: 3 times g: 1 time t: 7 times
We build the tree from the bottom by finding the two characters that have the smallest counts ("a" and "g" in this example). These are made to be a branch at the bottom of the tree, and at the top of the branch we write the sum of their two values (2+1, which is 3). The branches are labelled with a 0 and 1 (it doesn't matter which way around you do it).
We then forget about the counts for the two characters we just combined, but we use the combined total to repeat the same step: the counts to choose from are 3 (for the combined total), 3 (for "c"), and 7 (for "t"), so we combine the two smallest values (3 and 3) to make a new branch:
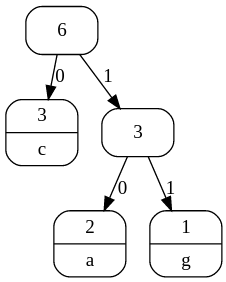
This leaves just two counts to consider (6 and 7), so these are combined to form the final tree:
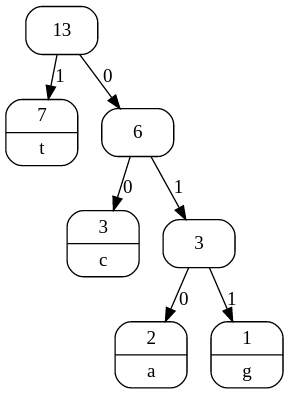
You can then read off the codes for each character by following the 0 and 1 labels from top to bottom, or you could use the tree directly for coding.
If you look at other textbooks about Huffman coding, you might find English text used as an example, where letters like "e" and "t" get shorter codes while "z" and "q" get longer ones. As long as the codes are calculated using Huffman's method of combining the two smallest values, you'll end up with the optimal code.
Huffman trees aren't built manually – in fact, a Huffman tree is built every time you take a photo as a JPG, or zip a file, or record a video. You can generate your own Huffman Trees using the interactive below. Try some different texts, such as one with only two different characters; one where all the characters are equally likely; and one where one character is way more likely than the others.
Other explanations of Huffman coding
There are video explanations of how to build a Huffman tree on Computerphile, one by Professor David Brailsford and another by Tom Scott
In practice Huffman's code isn't usually applied to letters, but to things like the lengths of run length codes (some lengths will be more common than others), or the match length of a point for a Ziv-Lempel code (again, some lengths will be more common than others), or the parameters in a JPEG or MP3 file. By using a Huffman code instead of a simple binary code, these methods get just a little more compression for the data.
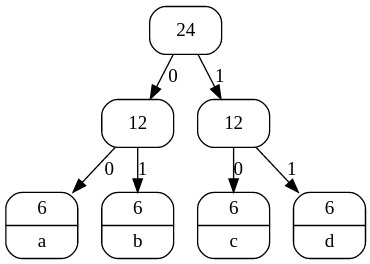
As an experiment, try calculating a Huffman code for the four letters a, b, c and d, for each of the following: "abcddcbaaabbccddcbdaabcd" (every letter is equally likely), and "abaacbaabbbbaabbaacdadcd" ("b" is much more common).
Solutions for Huffman codes Spoiler!
The tree for "abcddcbaaabbccddcbdaabcd" is likely to be this shape:
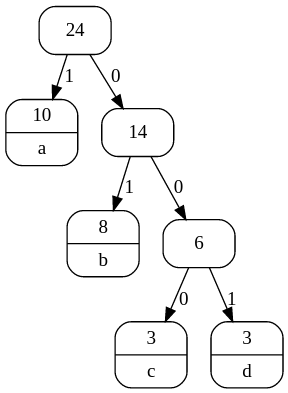
whereas the tree for "aabbabcabcaaabdbacbbdcdd" has a shorter code for "b"
The first one will use two bits for each character; since there are 24 characters in total, it will use 48 bits in total to represent all of the characters.
In contrast, the second tree uses just 1 bit for the character "a", 2 bits for "b", and 3 bits for both "c" and "d". Since "a" occurs 10 times, "b" 8 times and "c" and "d" both occur 2 times, that's a total of 10x1 + 8x2 + 3x3 + 3x3 = 44 bits. That's an average of 1.83 bits for each character, compared with 2 bits for each character if you used a simple code or were assuming that they are all equally likely.
This shows how it is taking advantage of one character being more likely than another. With more text a Huffman code can usually get even better compression than this.
Other kinds of symbols
The examples above used letters of the alphabet, but notice that we referred to them as "symbols". That's because the value being coded could be all sorts of things: it might be the colour of a pixel, a sample value from a sound file, or even a reading such as a the status of a thermostat.
As an extreme example, here's a Huffman tree for a dice roll. You'd expect all 6 values to be equally likely, but because of the nature of the tree, some values get shorter codes than others. You can work out the average number of bits used to record each dice roll, since 2/6 of the time it will be 2 bits, and 4/6 of the time it will be 3 bits. The average is 2/6 x 2 + 4/6 x 3, which is 2.67 bits per roll.
Another thing to note from this is that there are some arbitary choices in how the tree was made (e.g. the 4 value might have been given 2 bits and the 6 value might have been given 3 bits), but the average number of bits will be the same.