The regular languages that we looked at in previous sections are great for some common applications, but they can’t do the kind of processing needed to create programming languages and some other important applications.
For these we need grammars, which are more powerful than regular expressions.
In this section we’ll look at a particularly useful kind of grammar called the “context-free grammar”, or CFG.
Don’t worry too much about the long name; “context-free” just refers to what it can’t do.
A CFG is fairly simple, but it can achieve a lot of important work for us.
Bear in mind that the whole point of formal languages is that they make complicated things easy to do.
CFGs are widely used in computer science to write new programming languages, and to implement markup languages like HTML and XML.
They are very powerful because they allow a complicated system (like a compiler, or HTML display software) to be specified in a very concise way, and there are programs that will automatically take the grammar and build the system for you.
The grammars for conventional programming languages are a bit too unwieldy to use as initial examples (they usually take a few pages to write out), so we're going to work with some small examples here, but we’ll include parts of the grammars that are used for programming languages.
Grammar? Isn’t that about all the archaic rules for writing in English
Additional Information
With unusual grammar Yoda from Star Wars speaks.
Yet still understand him, people can.
The flexibility of the rules of English grammar means that you can usually be understood if you don't get it quite right, but it also means that the rules get very complicated and difficult to apply.
In Computer Science, “formal languages” use grammars that are much more predictable than grammars in human languages – that's why they're called formal languages!
When you're learning English, grammar can be a tricky topic because not only are there so many rules, but there are also so many exceptions – for example, you need an apostrophe if you write "plug into the computer's USB port", but you have to leave it out if you say "plug into its USB port".
Grammars in computer science are mainly used to specify programming languages and file formats, and these systems make a fuss even if you leave out just one bracket or comma!
But at least the errors are easy to explain, and easy to fix.
To show you how grammars work, we’re going to make you do the work that we’d normally get a computer to do with a grammar.
The ones we’ll start with are just “toy” examples; they’re simpler than most grammars that are used in practice, but they’re a good stepping stone.
Watch this video for a demonstration of the system we’ll use.
Now it’s your turn to experiment with a grammar!
In the interactive below you’ll see a large “S” in the middle.
Clicking on the S lets you replace it using one of the two rules (the technical name for the substitution rules is productions).
See if you can work out the productions you need to choose to generate the text in the white box - the generated text will show a green background if you get it right.
The “History” box will show the sequence of productions that you used.
Hint: you can get different challenges by clicking on the “Next” button.
Hit the “Reset” button to start over.
If it is “aabaa”, click on S → aSa, then S → aSa again, then S → b.
If it is “aaabaaa”, click on S → aSa, then S → aSa again, then S → aSa a third time, then S → b.
What is this puzzle solving?
Curiosity
By finding the productions to get from S to the string of characters you’ve been given, you are working out if the string is in the language of the grammar.
In practice, the string is often a whole computer program that is being checked - for example, if you write a program in a language like Python, Java, JavaScript or C#, before it can run it will be checked using a grammar designed for the language.
So the work you’ve just been doing is what happens every time you run or compile a program, only with a much bigger grammar and longer input string.
At the same time, it’s working out the structure of the program, which it will need to run it.
The examples you’ve tried so far are all strings of characters that are valid in the language.
Try solving this challenge - can you make the string “a” or “abaa” using the productions given?
If there’s no way to generate it, then the string isn’t in the language of the grammar.
The string has a syntax error.
You may have seen a syntax error before when you type in a program that doesn’t match the grammar of your programming language - it’s a grammar that is used to check if your text is in the language or not.
For example, the following Python code has a red underline at the end of the line:
This is because the grammar requires a colon (:) at the end of the for command, but it got the end of the line instead.
Every time you get a syntax error in a program, it is an example of a grammar at work.
As mentioned earlier, the rules, such as “S → aSa”, are called productions.
In this case, the whole process starts with an “S”, and ends up producing a mixture of “a”s and “b”s.
The characters “a” and “b” are called terminals because they can’t be replaced by anything - they are a terminal state.
“S” is called a “non-terminal” because it is on the left hand side of a production, and will be replaced with something else.
In most of our examples, non-terminals are written as a capital letter, and terminals are in lower case.
The productions you are working with accept strings of characters that have a particular pattern.
A string is accepted if there’s a way to generate it with the grammar.
Can you give an English description of what kind of pattern the grammar above accepts?
CFG Parsing Challenge #2 - Grammar description
These productions accept a “b” with an equal number of “a”s on each side of it.
How would you explain the kinds of strings that this accepts?
CFG Parsing Challenge #3 - Grammar description
The productions above accept strings that begin with some number of “a”s, followed by exactly the same number of “b”s.
Now here are some more challenges.
Note that the first production produces two “S” non-terminals, and although they are both called “S”, they don’t have to be the same.
The grammar above is a bit more complicated to describe in English, but you’ll probably get an idea of what sort of strings it accepts after you’ve tried a few examples.
The grammars we’ve used so far might not be directly useful, but hopefully you get the feel for how the productions in a grammar work.
Productions are used to check if the string you have is accepted by the rules of the grammar.
As with regular languages in the previous section, a string is either accepted by the grammar, or not.
For example, in the first grammar above, “aaabaaa” is accepted, but “bba” isn’t.
If you are given a string that isn’t in the grammar, then you won’t be able to find any combination of productions that can be used to create it.
An important thing about CFG productions is that they can be used to check rules that a regular language can’t
(Remember that regular languages use regular expressions and finite state automata).
You won’t be able to build an FSA that checks that the number of “a”s before the “b” is the same as the number after it - try to create one and you’ll see the issue!
Parsing
Jargon Buster
The process of working out the grammar rules that match a particular input string is called parsing.
The exercises you’ve been doing have been to parse the input using the context-free grammar you were given.
We sometimes explain how a string was parsed using a parse tree.
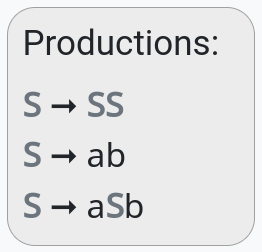
We’ll use this grammar as an example:
The following parse tree shows how you could use it to produce the string “abaabb”.
It starts with S at the top, and each branch in the tree (arrow) represents a production being used to replace a non-terminal.
For example, the top two arrows show S → SS, and the three-way branch from the right-hand S shows S → aSb (with the middle S then having its own two branches).
A context-free grammar is useful for creating programming languages. We’re going to look at a small part of a programming language now: mathematical expressions.
Expressions are used in both programming languages and spreadsheets. For example, a program might contain this statement, which adds one to the variable score:
score=score+1
The expression in this statement is score + 1 - it’s just a calculation.
The following expression calculates the area of a rectangle:
width*height
And the following expression might be used in a program to calculate the cost of a purchase:
cost*number_of_items*(discount/100)
In spreadsheets, an expression might look more like:
(A4 + B2) * C6
Expressions can have nested brackets like this:
(a*b)+(c*(d+e))
The first pair of brackets isn’t necessary, but they’ve been put in to make it easier to read.
Even the following is accepted in most programming languages, though the brackets aren’t very helpful:
(((((a)))))
The regular languages we used in earlier sections can’t keep track of nested brackets, but context-free grammars can.
We’re going to simplify things to start with by giving you a grammar that accepts simple expressions that only have single digit numbers.
All of these expressions could be typed into a language like Python, and should perform the calculation correctly (you could also type them into a spreadsheet, with an “=” sign at the front).
The following examples are valid expressions:
3+23*(4+2)((3))
But the following will cause an error:
3+3*4+2)(3))
For example, here’s what Python does with the last expression:
If you put it into a spreadsheet as =(3)) then you get an error like this:
Syntax error
Jargon Buster
If the string doesn’t match the grammar, then you have a syntax error - if a programming language ever tells you that you have a syntax error, it will have come from a formal language parsing what you typed in.
Doing these exercises is your turn to look for syntax errors in the input!
A grammar for working out these expressions can be experimented with in this interactive.
Click the next button after completing an expression to try another one.
Need help with the interactive?
Additional Information
In this grammar the non-terminal E represents an expression, and N represents a number.
An example string in the interactive was “(2+3)*(4+1)”, and its parse tree, which shows how to create the string using the grammar, would be as follows.
At the top level, the first E uses the production E → E*E, then each of those two “E”s uses E → (E), and so on.
Non-terminals: The capital letters in the productions (such as S, N, and E) are called “non-terminals”, because they don’t end up in the final string.
The letter S is often used in examples as the “starting” non-terminal, and in this case N stands for “number” and E stands for “expression”.
In practice all sorts of notation is used for non-terminals, but these are short ones to keep things simple to start with.
Terminals: The digits and lower case letters are “terminals” - once they are chosen, they can’t be replaced with anything further - they terminate a branch of the parse tree.
In practice, terminals are often recognised by a regular expression (they are usually things like variable names, keywords, or numbers).
In fact, the notation “0-9” in the productions is really a regular expression within the context-free grammar.
Context-free grammar: The kind of grammar we’re using here is called a context-free grammar (CFG), because it only has one non-terminal on the left of a production i.e. the non-terminal can be replaced regardless of its context.
There’s a more powerful system called a context sensitive grammar, but they are more complicated to work with and we won’t cover them here.
Parse tree exercises
Project
Try creating the parse trees for these expressions.
2+1
(3)*(5+1)
((4+1)*(8+3))+2
(3+2 - Note: This one has an error - you shouldn’t be able to find a parse tree for it!
You can also experiment with the productions to create these expressions in the following interactive.
Rather than write out a non-terminal on the left on multiple lines like this:
E → E + E
E → E * E
E → (E)
It is often simplified using a vertical bar:
E → E + E | E * E | (E)
More exercises to reinforce your understanding
Project
Here are a range of grammars and challenges for you to try.
None of them do anything that a CFG is likely to be used for in practice, but they will give you a feel for how CFGs work.
This grammar generates a pattern of “a” and “b” mixed together, then a “c”, then the original pattern backwards.
It can be strangely satisfying to solve, and it’s something you can’t check with a regular language (i.e. a regular expression or FSA).
This grammar generates strings that have a number of “a”s, followed by a number of “b”s, then a number of ”c”s that is the sum of the number of “a”s and “b”s.
This grammar generates strings of balanced brackets.
Normally there would be other symbols involved, but we’re just worrying if every opening bracket has a matching closed bracket.
It can get a bit hard to follow, but it’s all very logical!
Here’s a version of the grammar for an expression that will work if you paste the examples into a spreadsheet.
The only difference from the one above is that it puts an “=” sign at the front of the expression.
This grammar generates binary numbers that are multiples of three (3, 6, 9... which is 11, 110, 1001 in binary).
The examples include some numbers that aren’t multiples of 3, since you can’t be sure it’s working unless it rejects incorrect strings as well as accepting correct ones.
(As it happens, this language can also be generated using a regular expression.)
This grammar has a language that could have been implemented using a regular language - you can probably work out the FSA that would accept correct strings.
This is a silly grammar based on the English language.
English can’t usually be represented as a formal language, but this exercise gives you an idea of how the terminology in formal languages relates to ideas in English grammar.
Grammars are used to define programming languages like Python, Java, Javascript, C, C++, C# and so on, but they also define languages like HTML and XML.
When someone wants to write a program that processes files in one of these languages, they can write the production rules for the language, and then feed them into a system that automatically creates a program to process the language.
(An example of a system that can read in a CFG to help build a new programming language is Bison.)
Context-free grammars are particularly useful for working with languages that allow nesting.
We’ve already seen nesting when we had brackets within brackets in the expressions above.
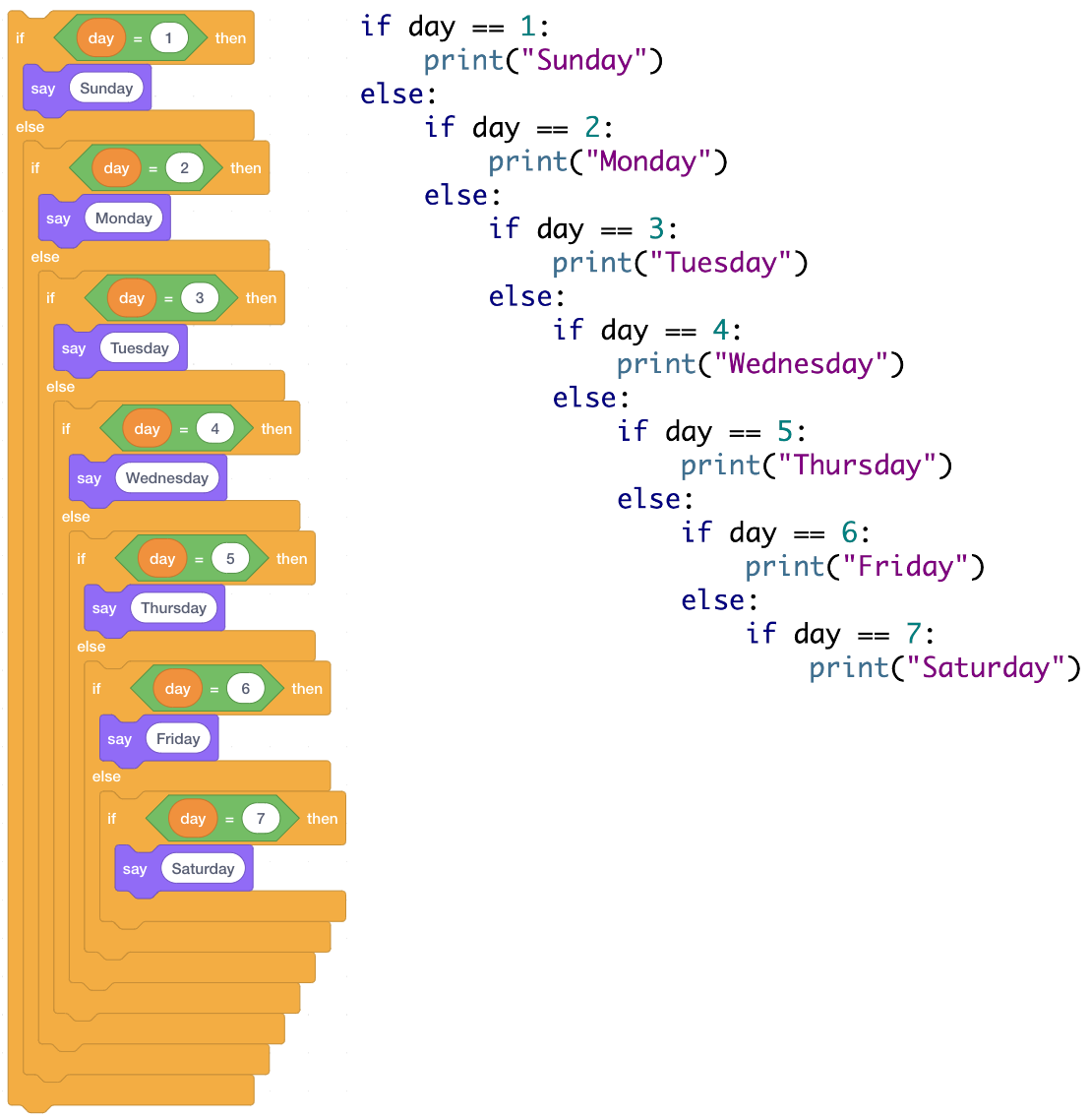
Another example that comes up in most programming languages is that you can have an “if” statement inside an “if” statement, or an “if” inside a “while” which is inside an “if”!
Here’s an example of some nested “if” statements in two languages.
(Note that these may not be the best way to write a program, but they are accepted by the grammar of the language.)
Usually there’s no limit to the nesting, even though it’s not great style to overuse it.
The notation we’ve been using for CFGs above is simplified to make it easy to read, but here is a link to the actual grammar for the Python language.
In this notation, terminals are in quote marks. For example, the definition of an “if_stmt” (the non-terminal representing an if statement) includes:
The last line means that an “if” statement starts with the terminal “if”, then has an expression (that’s the true/false decision in an “if” statement), a colon, and a block, followed by an optional “else” block (indicated by the square brackets).
If you search the Python language grammar for the non-terminal “block:” in the grammar, you’ll see that it can be an indented group of statements, or a simple statement.
If you keep following up on these, you’ll find out that a statement can (eventually) be another “if” statement.
These two productions use the vertical line “|” as a shortcut to show that they are alternatives for an “if_stmt”.
Grammars like this are the way that a programming language designer specifies the rules of the language.
The entire grammar for Python is only about 500 lines long, which might seem like a lot, but it’s not bad considering that it specifies the syntax rules for an entire programming language, and is able to process any Python program that anyone will ever come up with!
In practice, regular expressions do the simple tasks, like recognising numbers and variable names, and the grammar is used for the things that the regular expression can’t do.
In the previous section we used regular expressions, which could define strings from regular languages, and could be implemented using a finite state automaton.
In this section we’ve used the more powerful context-free grammar, which can define strings from context-free languages.
These can be implemented using something called a push-down automaton (PDA), which is a more powerful version of a finite state automaton (FSA).
We won’t look at how a push-down automaton works here, but you were doing the job of a PDA when you were applying a context-free grammar in the challenges above.
Context-free grammars can check languages that regular expressions can’t.
In fact, every regular language can be checked by a context-free grammar, but not the other way around.
We could just use CFGs instead of regular expressions, but they are a bit more unwieldy to use, so we use a regular expression if we can (e.g. to recognise variable names, email addresses or numbers), and bring in a CFG if the language calls for it.
Context-free grammars are pretty versatile, but some slightly more powerful types of grammars are sometimes needed for some languages.
Computer scientists have many variations - you may hear about things like “Context-sensitive grammars”, “parsing expression grammars” or “LL(k) grammars”.
They use many of the same principles as a CFG, but are useful in particular situations.
Computer scientists who design new languages and write software to process languages are able to use these tools to make the process much simpler and more reliable.
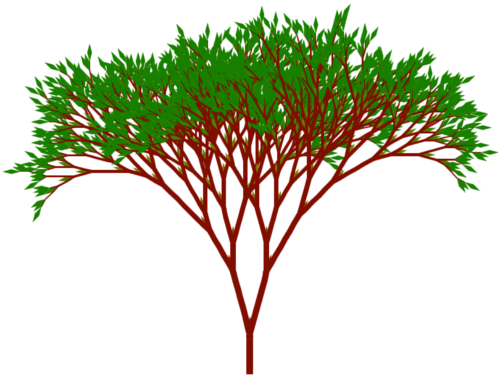
The context free art program enables you to specify images using a context-free grammar.
For example, the following pictures of trees are defined by just a few rules that are based around a forest being made of trees, a tree being made of branches, and the branches in turn being made of branches themselves!
These simple definitions can create images with huge amounts of detail because the drawing process can break down the grammar into as many levels as required.
You can define your own grammars to generate images, and even make a movie of them being created, like the one below.
Of course, if you do this as a project make sure you understand how the system works and can explain the formal language behind your creation.
The JFLAP program also has a feature for rendering "L-systems", which are another way to use grammars to create structured images.
You'll need to read about how they work in the JFLAP tutorial.
There are some more sample files at cs.duke.edu to get you inspired (look at the files starting "ex10...").
and here's an example of the kind of image that can be produced:
Analyse a simple piece of music in terms of a formal grammar.
There are even more powerful languages than those mentioned here, but they are much harder to work with, and are often used to explore the boundaries of what can be done with computation.